
Este artículo forma parte de una serie de publicaciones en las que se presenta información relevante sobre la investigación que se ha llevado a cabo para comprobar y valorar la aplicabilidad de nuevas tecnologías como la Inteligencia Artificial en el ámbito médico y sanitario.
A continuación, se explicarán una serie de conceptos, a los que se harán alusión en el resto de publicaciones. Antes de ello, simplemente informar que las explicaciones partirán de elementos menos técnicos hacia elementos más complejos.
Los modelos de inteligencia artificial son algoritmos computacionales diseñados para simular y replicar las habilidades cognitivas y de razonamiento humanas en máquinas. Su finalidad es permitir que los ordenadores aprendan, se adapten a situaciones y realicen tareas que precisan de presencia e inteligencia humana. Estas acciones pueden ser el reconocimiento de patrones, la toma de decisiones o el procesamiento del lenguaje natural.
Dentro del marco de la Inteligencia Artificial existen varios tipos de modelos, como pueden ser las redes neuronales artificiales, de aprendizaje automático o de procesamiento del lenguaje natural. Uno de ellos, y sobre el que está basado esta serie de artículos, son los modelos de lenguaje. Estos se entrenan para predecir la probabilidad de una secuencia de palabras, lo que les permite generar texto coherente y gramaticalmente correcto. Los modelos permiten, entre otras muchas utilidades, el desarrollo de chatbots o asistentes virtuales.
El contexto abarca la información previa y el conocimiento que se emplea para comprender y generar texto coherente. Está formado por una variedad de elementos, tales como las oraciones anteriores, preguntas planteadas, declaraciones previas o conceptos discutidos.
El contexto desempeña un papel fundamental al interactuar con modelos de lenguaje, ya que permite conocer la intención detrás de una solicitud y generar respuestas adecuadas. Es importante destacar que el tamaño y la relevancia del contexto pueden variar según el modelo y la tarea específica. Al proporcionar un contexto claro y acertado, generalmente, se facilita la obtención de respuestas más útiles y acordes al contexto en cuestión.
En el marco de la Inteligencia Artificial, un prompt hace referencia a la instrucción que se le proporciona a un modelo de lenguaje con el fin de obtener una respuesta específica o generar texto coherente. El prompt establece el contexto y guía al modelo en la dirección deseada.
Los prompts se utilizan para solicitar información, hacer preguntas, plantear problemas o cualquier tipo de interacción con el modelo. Pueden ser una sola oración, un párrafo o incluso varios, dependiendo de la complejidad de la tarea o la respuesta buscada.
La calidad y claridad del prompt son fundamentales para obtener resultados precisos y relevantes del modelo. Un prompt bien formulado debe proporcionar la información necesaria y ser lo suficientemente específico para que el modelo pueda entender la solicitud y generar una respuesta adecuada.
Los tokens son unidades individuales de texto que se emplean para dividir y representar el contenido de un texto. Un token puede ser una palabra, un número, un signo de puntuación o cualquier otra unidad de texto significativa.
En los modelos de lenguaje, los tokens son fragmentos de texto que el modelo procesa de forma individual. Estos modelos tienen una limitación en el número máximo de tokens que pueden procesar en una sola solicitud, lo que implica fragmentarlo en caso de textos largos. La cantidad de tokens también influye en el rendimiento y el coste de los modelos de lenguaje, ya que se suele cobrar por la cantidad de tokens empleados.
También es relevante considerar el lenguaje en el que se realiza este procesamiento. En el caso del inglés, aproximadamente cada token representa, al menos, 4 caracteres, mientras que, en español, cada token equivale a 2,5 caracteres. Este aspecto resulta significativo, ya que tiene un impacto claro en los cálculos de costes y en las estrategias que debemos seguir al crear los prompts.
En Inteligencia Artificial se conoce como tokenización al proceso esencial de dividir el texto en tokens. Es un paso fundamental en el procesamiento del lenguaje natural y en los modelos de lenguaje. Al dividir el texto en tokens, se genera una representación numérica que el modelo puede entender y procesar. Además, ayuda a capturar mejor la semántica y las relaciones entre las palabras de un texto.
En algunos casos, la tokenización puede implicar técnicas adicionales, como la normalización del texto, la eliminación de signos de puntuación o la separación de palabras compuestas. Tenemos un artículo comentando en detalle este proceso.
A la hora de trabajar con los distintos modelos de lenguaje y sistemas de Inteligencia Artificial tenemos que tener en cuenta una serie de parámetros claves. Estos elementos nos permitirán ajustar las respuestas que recibamos.
Este parámetro sirve para controlar la diversidad de las respuestas. Limita el número de palabras más probables a considerar en cada paso del proceso. Funcionamiento:
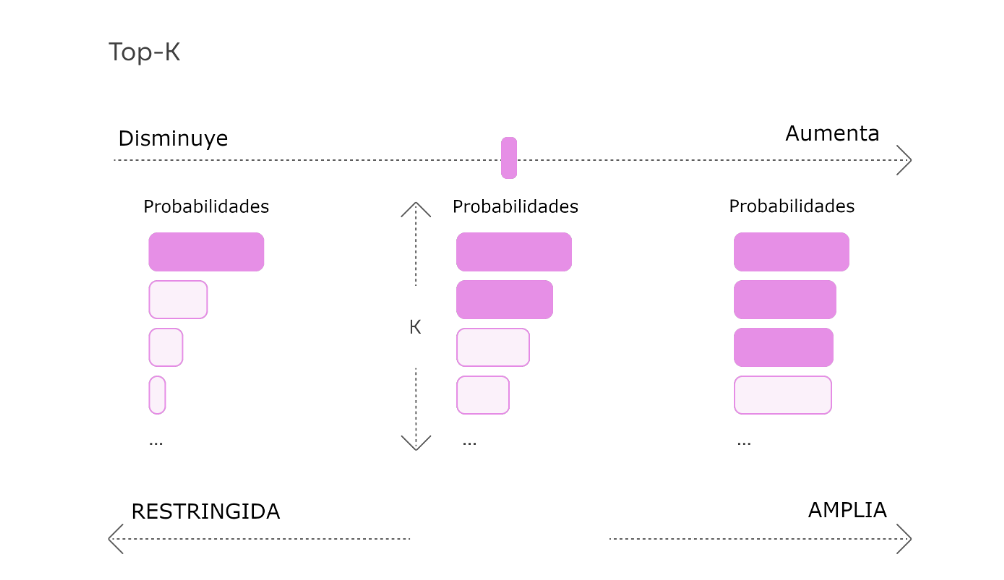
Un valor top_k más alto hace que el sistema tenga en cuenta un mayor número de palabras, generando respuestas más aleatorias.
Un valor top_k más bajo reduce la selección a sólo las palabras más probables, con lo que se obtiene un resultado más centrado y determinista.
Esta variable permite especificar un umbral de probabilidad acumulada. El modelo sólo tendrá en cuenta las palabras cuya probabilidad acumulada sea inferior o igual a la marca especificada. Funcionamiento:
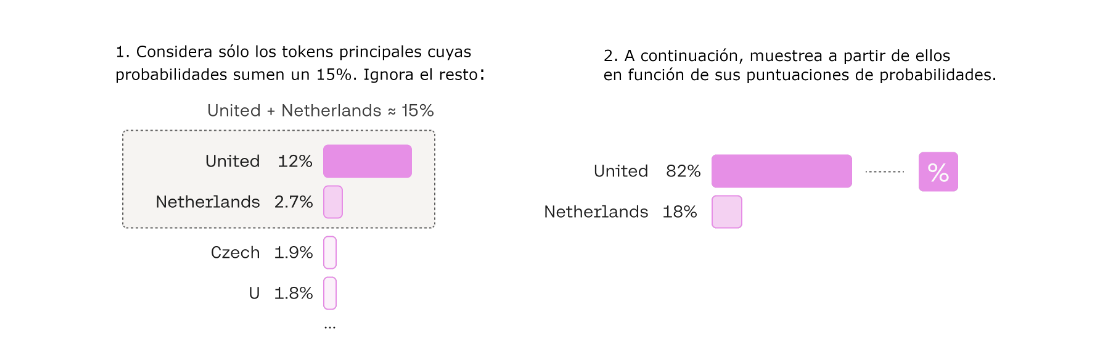
Un valor top_p cercano a 1 permite considerar más palabras y aumenta las posibilidades de seleccionar palabras menos comunes o diversas.
Un valor top_p cercano a 0 restringe la selección a palabras de alta probabilidad, lo que da lugar a respuestas más específicas y deterministas.
Si top_p y top_k se encuentran activos, primero actuará top_p y después top_k.
Sirve para controlar la aleatoriedad de las respuestas del modelo. Ajusta la distribución de probabilidades durante el proceso de muestreo, influyendo en la diversidad y creatividad de las respuestas del modelo. Funcionamiento:
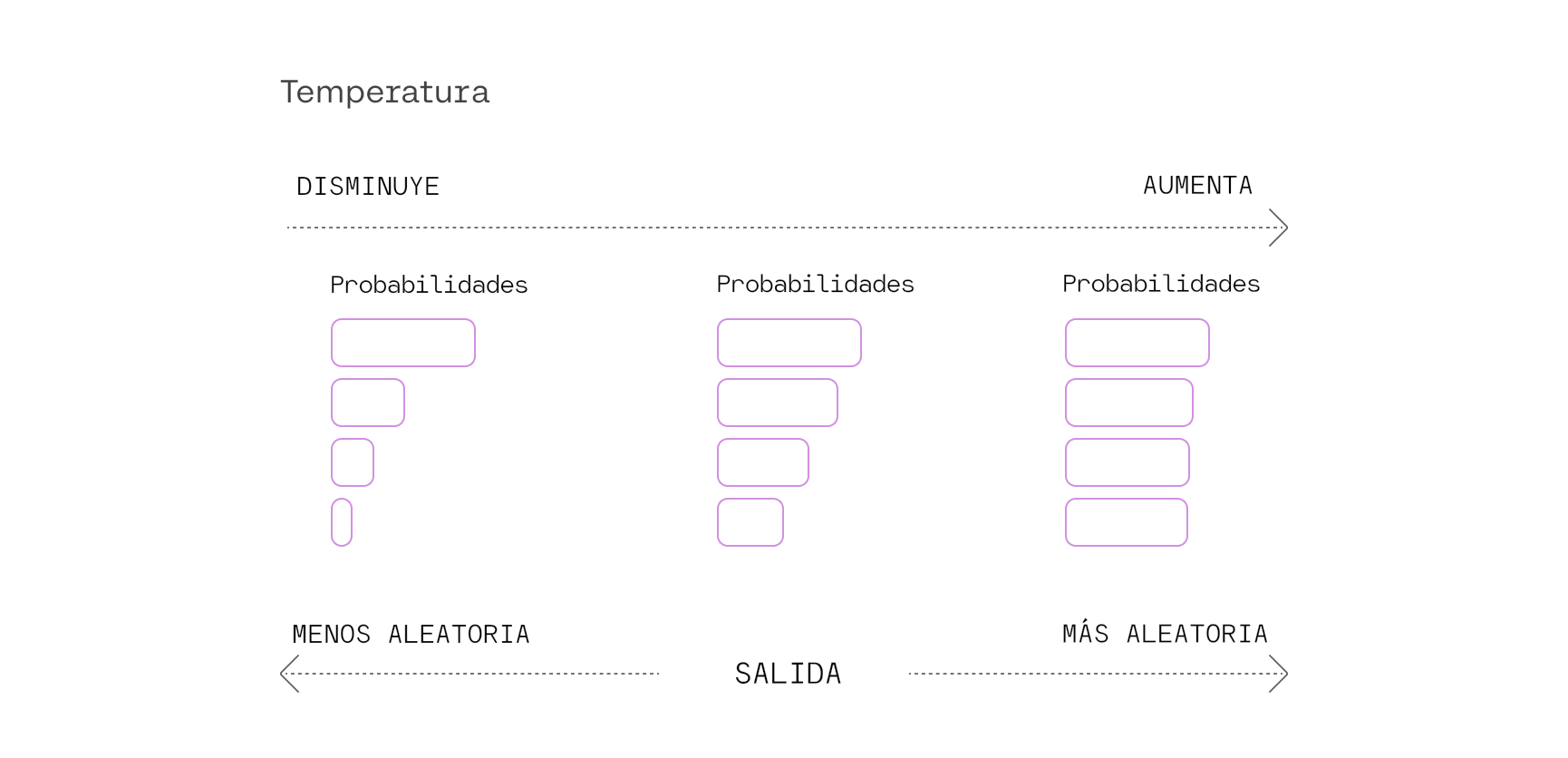
Estos parámetros pueden emplearse para contrarrestar la tendencia del modelo a repetir de manera literal el texto de la pregunta. Esto se consigue ajustando las probabilidades de los tokens en cada paso de generación, de forma que los tokens que ya han aparecido en el texto tengan menos probabilidades de ser generados. Existen distintos tipos dependiendo del modelo:
Este parámetro es usado para reducir la probabilidad de generar nuevos tokens que aparecen al menos una vez en el enunciado o en la respuesta.
Ejemplo: si tenemos el enunciado "dos médicos, tres médicos, cuatro médicos" la probabilidad de los tokens "dos", "tres", "cuatro" y "médicos" disminuirá (en el mismo valor), aunque "médicos" aparezca más.
Este valor se usa para reducir la probabilidad de generar nuevos tokens que aparezcan al menos una vez en el enunciado o en la respuesta, en proporción al número de apariciones.
Ejemplo: ante el enunciado "dos médicos, tres médicos, cuatro médicos" la probabilidad de los tokens "dos", "tres" y "cuatro" disminuirá un valor determinado y la probabilidad de "médicos" lo hará en un valor mayor.
Elemento encargado de reducir la probabilidad de generar nuevos tokens que aparezcan en el enunciado o en la compleción, en proporción a la frecuencia (normalizada a la longitud del texto) de sus apariciones en el texto. El uso de este método es beneficioso en textos largos, ya que la repetición de algunas palabras es menos problemática que en textos cortos.
Made with in Spain
© 2013 - 2026 Xoborg Technologies S.L. Todos los derechos reservados. C. Teso de San Nicolás, 17, Semisótano local 1, Salamanca 37008, Castilla y León, España.