
Este artículo forma parte de una serie de publicaciones en las que se presentan los datos destacables y conclusiones de la investigación que se ha llevado a cabo para comprobar y valorar la aplicabilidad de nuevas tecnologías como la Inteligencia Artificial en el ámbito médico y sanitario.
Tras analizar, en este artículo, las opciones de pago por uso, nos disponemos a explorar y probar las diversas posibilidades que ofrecen los modelos de ejecución local. Este enfoque tiene como objetivo principal la seguridad y privacidad de los datos.
También queremos evaluar la viabilidad de realizar el procesamiento en máquinas locales o servidores específicos, con el fin de determinar si un conjunto de servidores puede manejar eficientemente la tarea asignada, considerando un alto número de consultas y clientes simultáneos.
Se buscarán soluciones de código libre y actualizadas, para soportar los últimos modelos e implementaciones disponibles, y que permitan el uso comercial del servicio.
Antes de adentrarnos en el análisis de las diferentes opciones, es importante proporcionar una breve explicación sobre el funcionamiento de estos sistemas.
En primer lugar, partimos de un modelo de datos generado y entrenado por diversas empresas y organismos. Estos presentan una gran variedad de tamaños, desde aquellos que ocupan pocos gigabytes hasta otros que requieren considerablemente más espacio. Cuando interactuamos con el modelo, este debe ser cargado, total o parcialmente, en memoria.
En el ámbito empresarial, es común utilizar servidores equipados con tarjetas gráficas, las cuales presentan una gran cantidad de memoria destinada a cargar estos modelos. En el caso de modelos muy pesados, es posible que se requiera el empleo de múltiples tarjetas gráficas o incluso clústeres de servidores.
El empleo de tarjetas gráficas para la carga y ejecución de modelos no es cuestión trivial. Estos componentes están diseñados principalmente para el cálculo paralelo de datos, lo que proporciona un rendimiento muy superior, para estas tareas, al comportamiento secuencial del procesador. Esto permite a grandes empresas, con servidores y centros de datos, presentar respuestas de manera rápida.
En caso de querer ejecutarlo en local, se puede seguir el mismo enfoque, pudiendo usar tanto una tarjeta gráfica dedicada como el procesador para computar las respuestas. Con este último enfoque se presentan una serie de problemas que veremos a continuación.
Una de las primeras soluciones que podemos encontrar es GPT4All, una herramienta gratuita, local y con un alto nivel de privacidad. Una de las características más importantes es que no requiere de tarjeta gráfica ni conexión a internet para funcionar. Esta herramienta presenta una amplia variedad de modelos, entre los cuales se encuentran falcon, groovy, orca-mini o mpt-7b, todas ellas permitiendo su utilización con fines comerciales.
Estos modelos tienen un tamaño que oscila entre 3GB y 8GB, son versiones modificadas y mantenidas por Nomic AI, la empresa responsable del proyecto. Existen una serie pruebas de rendimiento que nos permiten seleccionar el modelo que más se alineen con nuestros requisitos, por lo general estos modelos presentan un rendimiento cercano al de davinci-003 de OpenAI.
GPT4All ofrece distintas opciones para trabajar con los modelos. La más simple y directa consiste en la instalación de la aplicación de escritorio. Desde ella podremos descargar e interactuar con los distintos modelos.
También presenta la opción de utilizar este programa como un servidor al que realizarle consultas. Estas dos soluciones presentan una clara limitación, no se pueden efectuar consultas simultáneas, es decir, no existe concurrencia. Esta solución puede ser empleada por un único cliente, pero no es adecuado si queremos atender a varios.
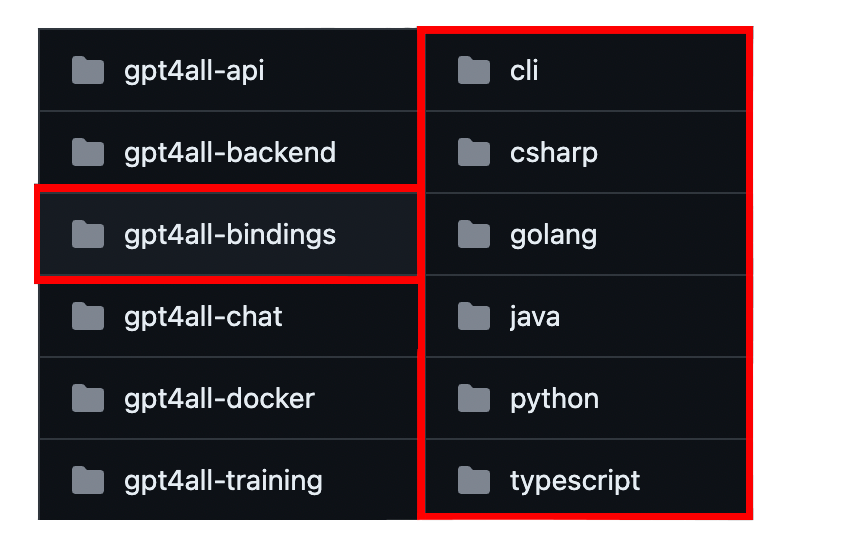
Además de estas propuestas, GTP4All nos permite la opción de los "bindings". Se trata de simples enlaces a las bibliotecas del backend de los modelos de C/C++ sobre los que está desarrollado el proyecto. En el momento de escritura de este artículo están disponibles estos lenguajes:
Para el propósito de esta investigación, haremos uso de la versión de Python. Si modificamos este programa y le añadimos funcionalidad API podremos llevar a cabo consultas desde cualquier dispositivo. Esta implementación puede hacerse con Flask o FastAPI. En las pruebas efectuadas tanto en un equipo local como en un servidor remoto, el tiempo de respuesta oscila entre 12 y 17s, dependiendo del tamaño de esta, frente a los 2 a 5s en soluciones de pago.
Para confirmar que se trata de una limitación debido al procesamiento de los modelos y no por la implementación, se han realizado una serie de pruebas controlando el número de hilos disponibles para la respuesta ante un prompt. Las pruebas fueron llevadas a cabo en un servidor remoto con 8 núcleos y 16GB de RAM, ejecutando el código de Python con Flask. Antes de analizar los resultados en detalle, indicar que estos son aproximados, dependen del mensaje que se envíe y del número de tokens que se generen.
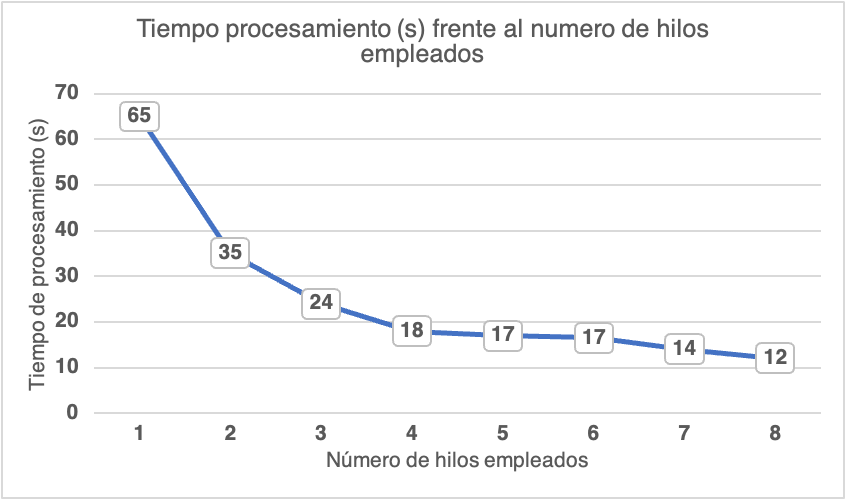
Como podemos comprobar, el rendimiento mejora claramente al ir aumentando el número de hilos de procesamiento. Sin embargo, esta mejora no es lineal y se reduce a partir de 4. Además, es importante destacar la memoria RAM necesaria para ejecutar adecuadamente el programa, dependiendo del modelo, 4 GB y 8GB. El programa no se ha sido creado para atender a varias llamadas simultáneas, no existe posibilidad de concurrencia.
La última opción disponible en GPT4All consiste utilizar su API REST. Nos permitirá ejecutar y construir imágenes docker con la aplicación en FASTAPI. Se han realizado pruebas sobre esta implementación, obteniendo resultados y funcionamiento similares a los logrados con la versión en Python.
Después de mostrar las limitaciones de GPT4All continuamos explorando las posibles soluciones de código libre. Entre esas alternativas disponibles tenemos LocalAI, se trata de una API REST, que permite ejecutar los modelos de manera local, incluso en hardware de consumo.
Al igual que GPT4All, no requiere el uso de GPU para funcionar. Tampoco se requiere de conexión a internet y como novedad ofrece la aceleración por tarjeta gráfica en modelos compatibles con "llama.cpp". Otro aspecto destacable es la opción de cargar el modelo la primera vez que se ejecuta y mantenerlo en memoria para obtener inferencias más rápidas.
Una vez que el sistema se encuentre en funcionamiento podremos hacer peticiones 'curl' a la dirección y puerto que hayamos indicado. Para comprobar el comportamiento frente a consultas concurrentes se ha creado un programa para que efectúe una serie de consultas aleatorias de manera simultánea. Cada una de las respuestas se ha impreso junto al tiempo que ha tomado para completarse.
| Cantidad de consultas simultáneas | Tiempo medio de respuesta (s) |
|---|---|
| 2 | 18,5 |
| 3 | 13 |
| 10 | 15 |
| 15 | 17,5 |
| Total | Media |
| 30 | 16 |
Como podemos verificar en los resultados, los tiempos empleados varían entre ejecuciones dependiendo del tamaño de la respuesta, dado que no es enviada hasta que no se obtiene completamente. También podemos ver que existe soporte ante varias consultas simultáneas, pero no concurrencia. Si bien el programa sigue su ejecución ante nuevas consultas, el sistema no puede responder a más de una consulta de manera simultánea.
Si quisiéramos conseguir concurrencia, podríamos usar un cluster de varios contenedores con implementaciones de este servicio. Para atender a las peticiones se precisaría de un balanceador de carga que reparta las peticiones según se realicen. Pese a implementar este tipo de solución, existiría un tiempo de procesamiento alto, en torno a 10 segundos, en cada una de las consultas. También hay que tener en cuenta el coste de los servidores, balanceadores de carga y mantenimiento necesario para que esta solución funcione adecuadamente.
Aunque es posible utilizar una tarjeta gráfica para resolver las consultas, tanto la implementación en local como el empleo de un servidor en remoto con este hardware presenta un coste muy superior al de emplear una solución como la de Azure.
Dadas estas limitaciones, es recomendable descartar estas soluciones.
Tanto GPT4All como LOCALAI son las soluciones más avanzadas en el campo de la inteligencia artificial de código libre. Pese a que permiten usar una gran variedad de modelos y efectuar el procesamiento de las consultas en servidores dedicados o incluso equipos locales, no se encuentran al nivel de madurez ni rendimiento que presentan las soluciones de pago. Sin embargo, se pueden llegar a implementar en soluciones en las que la concurrencia o el tiempo de respuesta no sean factores limitantes.
Made with in Spain
© 2013 - 2026 Xoborg Technologies S.L. Todos los derechos reservados. C. Teso de San Nicolás, 17, Semisótano local 1, Salamanca 37008, Castilla y León, España.