
Como hemos visto en el artículo sobre implementaciones locales, podemos emplear distintas herramientas para inferir sobre modelos de datos en máquinas o servidores remotos. Las soluciones nombradas en la publicación son GPT4All y LocalAI, aunque existen otras como son oobabooga o LlamaGPTJ.
A continuación, indicaremos los distintos pasos para configurar y trabajar con las herramientas que se han estudiado, este artículo presenta un enfoque técnico con los comandos necesarios y código de ejemplo.
Antes de comenzar es importante recalcar que estos proyectos son actualizados diariamente, por lo que ciertas prestaciones pueden cambiar, ser actualizadas o desaparecer, por ello recomendamos revisar los repositorios de cada uno de los proyectos.
Como comentamos en el artículo existe una gran variedad de opciones con este proyecto. En este momento tiene versión de API REST, múltiples bindings o la opción de ejecutar tanto la aplicación independientemente o hacer que funcione como servidor de peticiones. En el repositorio del proyecto podemos encontrar las versiones más actualizadas.
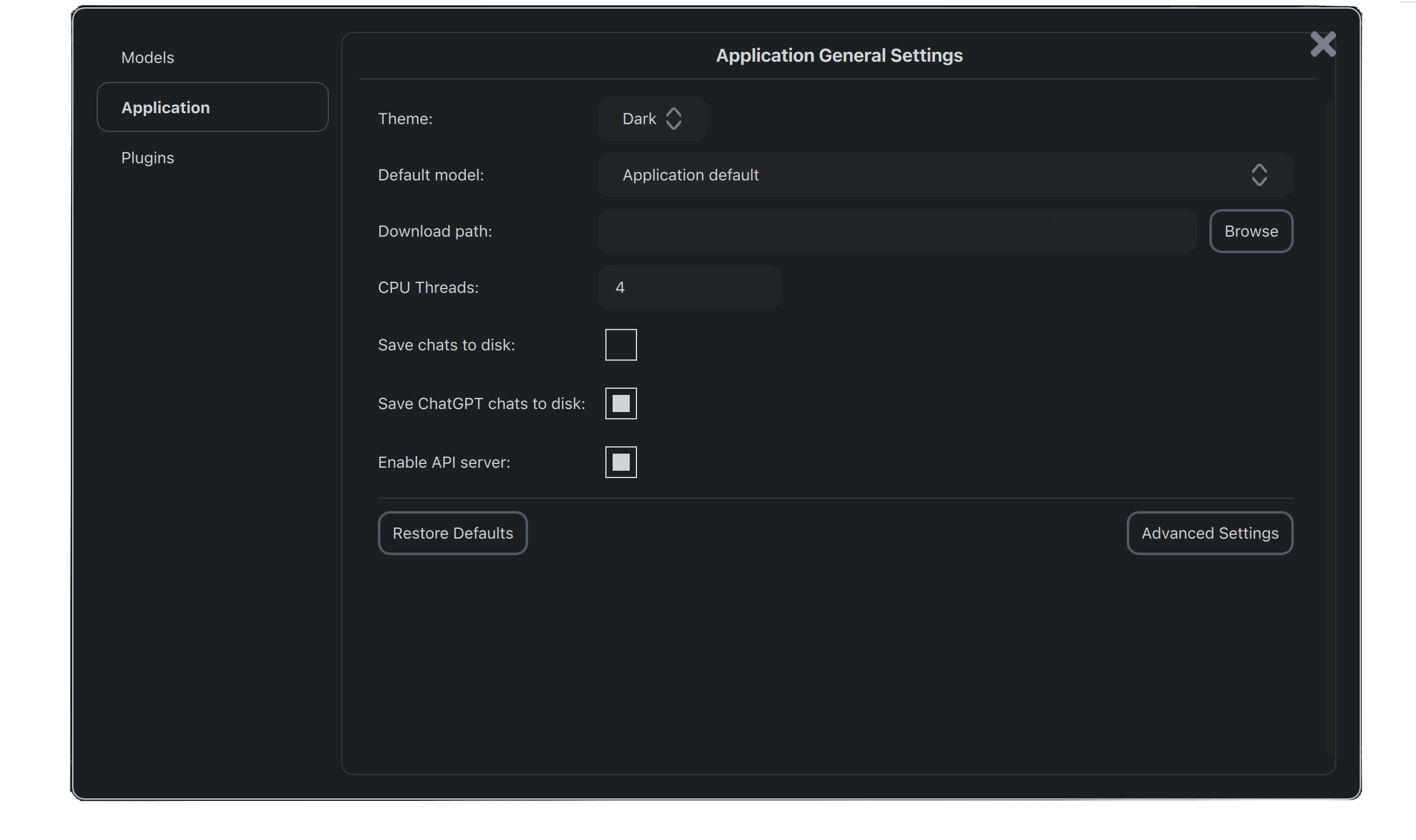
Para poder trabajar con la aplicación simplemente debemos descargarnos el instalador de la aplicación. Cuando esté instalada, podemos elegir entre los distintos modelos disponibles. Al seleccionarlos, usando la interfaz, podremos inferir sobre ellos. Dentro de la configuración podemos habilitar la opción de emplear la aplicación como servidor API, como se puede ver en la imagen.
Para poder inferir sobre estos modelos, utilizamos una sintaxis similar al de la API de OpenAI con unas pequeñas modificaciones. Este sería el código de ejemplo para la ejecución de una consulta:
import openai
openai.api_base = "http://localhost:4891/v1"
openai.api_key = "not needed for a local LLM"
# Escribimos el prompt y seleccionamos el modelo
prompt = "The capital of Spain is "
model = "gpt4all-j-v1.3-groovy"
# Hacemos la petición
response = openai.Completion.create(
model=model,
prompt=prompt,
max_tokens=50,
temperature=0.28,
top_p=0.95,
n=1,
echo=True,
stream=False
)
# Imprimimos la respuesta
print(response)
Otra opción es emplear los enlaces específicos para cada lenguaje sobre los modelos backend de C/C++. En este momento hay disponible para:
Para la explicación se emplearán Python, pero el proceso es similar en el resto de lenguajes. Simplemente, deberemos ejecutar uno a uno los siguientes comandos:
pip install gpt4all
# Configuración de llmodel
git clone --recurse-submodules https://github.com/nomic-ai/gpt4all
cd gpt4all/gpt4all-backend/
mkdir build
cd build
cmake ..
cmake --build . --parallel
# Configuración del paquete de Python
cd ../../gpt4all-bindings/python
pip3 install -e
Para realizar pruebas podemos emplear tanto la consola como un script de Python, si el modelo que seleccionemos no se encuentra en nuestro equipo, se descargará antes de ejecutarlo:
from gpt4all import GPT4ALL
model = GPT4ALL("ggml-gpt4all-j-v1.3-groovy.bin")
output = model.generate("The population of Spain is ", max_tokens =3)
print(output)
Esta solución puede ser mejorada empleando FLASK o FASTAPI para aceptar consultas desde otros equipos.
Empezaremos por Flask, seguiremos las siguientes órdenes:
#Creamos el entorno virtual
mkdir proyecto
cd proyecto
python3 -m venv .venv
. .venv/bin/activate
Una vez dentro del entorno virtual, instalamos Flask:
pip install Flask
El código será algo similar a lo siguiente, indicar que este código emplea archivos HTML y funcionalidad con JavaScript para mostrar una interfaz. Si se quieren realizar consultas deberemos modificar el valor de 'data'.
from gpt4all import GPT4All
from flask import Flask, render_template, jsonify, request
app = Flask(__name__)
gptj = GPT4All("ggml-gpt4all-j-v1.3-groovy")
#Configuración de las llamadas de FLASK
@app.route('/', methods=['GET', 'POST'])
def welcome():
return render_template('index.html');
#Si se envía un mensaje se genera la consulta.
@app.route('/mensaje', methods=['GET'])
def handle_data():
data = request.args.get('userInput')
messages = [{"role":"system", "content":"You are a assistant."},
{"role":"user","content":data}]
texto = gptj.chat_completion(messages)
return jsonify(texto["choices"][0]["message"]["content"])
if __name__ == '__main__':
app.run(host='127.0.0.1', port=7005)
Y para ejecutarlo deberemos usar
# Únicamente una primera vez
export FLASK_APP = 'miarchivo.py'
# Todas las veces que queramos ejecutarlo usaremos
flask run
FastAPI tendrá un funcionamiento similar a Flask, para instalarlo usamos:
pip install "fastapi[all]"
A continuación, se mostrará el código equivalente al apartado anterior, pero para FastAPI.
from typing import Union
from fastapi import FastAPI, Request
from fastapi.responses import HTMLResponse
from fastapi.staticfiles import StaticFiles
from fastapi.templating import Jinja2Templates
from fastapi.responses import JSONResponse
from gpt4all import GPT4All
app = FastAPI()
app.mount("/static", StaticFiles(directory="static"), name="static")
templates = Jinja2Templates(directory="templates")
#Cargamos el modelo.
gptj = GPT4All(model_name="ggml-gpt4all-j-v1.3-groovy.bin")
#Configuramos las llamadas de FASTAPI
@app.get("/", response_class=HTMLResponse)
async def home(request: Request):
return templates.TemplateResponse("index.html", {"request":request})
@app.get("/mensaje")
def handle_data(userInput: str):
ent = userInput
messages = [{"role":"system", "content":"You are a assistant."},
{"role":"user","content":ent}]
texto = gptj.chat_completion(messages, verbose = False)
return JSONResponse(content=texto["choices"][0]["message"]["content"])
Para ejecutarlo:
uvicorn main:app --reload
También podemos usar una imagen de Docker que ejecute una aplicación FastAPI para servir de inferencia sobre modelos. La API coincide con la especificación de la API de OpenAI. Primero necesitamos construir la imagen de Docker, antes debemos clonar el proyecto, con el siguiente comando.
git clone --recurse-submodules https://github.com/nomic-ai/gpt4all
cd gpt4all/gpt4all-api
DOCKER_BUILDKIT=1 docker build -t gpt4all_api --progress plain -f gpt4all_api/Dockerfile.buildkit .
Para inicializarlo utilizaremos
docker compose up --build gpt4all_api
Una vez que se haya inicializado la aplicación de FastAPI se puede acceder a la documentación del servicio en la dirección:
localhost:80/docs
Para inferir podemos ejecutar el siguiente código de ejemplo:
import openai
openai.api_base = "http://localhost:4891/v1"
openai.api_key = "not needed for a local LLM"
def test_completion():
model = "gpt4all-j-v1.3-groovy"
prompt = "Who is Rafael Nadal?"
response = openai.Completion.create(
model=model,
prompt=prompt,
max_tokens=50,
temperature=0.28,
top_p=0.95,
n=1,
echo=True,
stream=False
)
assert len(response['choices'][0]['text']) > len(prompt)
print(response)
Los modelos, de forma predeterminada, se almacenan en /Users/user/.cache/gpt4all.
GPT4All presenta una gran variedad de opciones a la hora de inferir sobre distintos modelos. Incluyendo la opción de entrenar ciertos modelos. Por último, recalcar que la opción de usar las imágenes de Docker del proyecto se encuentra en este momento en desarrollo.
Por otro lado, tenemos LocalAI, se trata de una API escrita en Go que funciona como adaptador de OpenAI, permitiendo que el software ya desarrollado con los SDK de OpenAI se integre sin problemas con LocalAI. Esto se consigue empleando varios backends de C++ para efectuar inferencia en modelos de lenguaje grandes utilizando tanto CPU como GPU.
Antes de comenzar, es necesario instalar Docker-compose para poder ejecutar el programa.
#Descargamos la última versión disponible en este momento.
sudo curl -L "https://github.com/docker/compose/releases/download/2.20.2/docker-compose-$(uname -s)-$(uname -m)" -o /usr/local/bin/docker-compose
# Le concedemos permisos
sudo chmod +x /usr/local/bin/docker-compose
A continuación, se mostrarán los pasos a seguir para su instalación, usando como ejemplo el modelo GPT4LL-J.
#Clonamos el repositorio
git clone https://github.com/go-skynet/LocalAI
cd LocalAI
#Descargamos el modelo y lo almacenamos en la carpeta models/
wget https://gpt4all.io/models/ggml-gpt4all-j.bin -O models/ggml-gpt4all-j
#Usamos una plantilla de ejemplo
cp -rf prompt-templates/ggml-gpt4all-j.tmpl models/
docker-compose up -d --pull always
# O también con la orden
docker-compose up -d --build
En el último paso, dependiendo del entorno donde se ejecute, es posible que genere problemas. Para solucionarlos es recomendable seguir los siguientes pasos:
#Instalamos kind
curl -Lo ./kind https://kind.sigs.k8s.io/dl/v0.20.0/kind-linux-amd64
# Creamos el cluster
kind create cluster
Y en vez de los comandos anteriores, emplear:
docker-compose pull && docker-compose up
Si todo ha funcionado tendremos la API accesible en la dirección IP de la máquina y en el puerto 8080, estos parámetros pueden cambiarse en la configuración de Docker. Para realizar pruebas podemos emplear.
#Ante esta consulta
curl http://localhost:8080/v1/models
# Obtenemos como respuesta -> {"object":"list","data":[{"id":"ggml-gpt4all-j","object":"model"}]} que es el modelo que tenemos instalado
Si queremos realizar consultas podemos usar
curl http://localhost:8080/v1/chat/completions -H "Content-Type: application/json" -d '{
"model": "ggml-gpt4all-j",
"messages": [{"role": "user", "content": "Is 33 a prime number?"}],
"temperature": 0.9
}'
Al tratarse de consultas con curl podemos modificarlas a cualquier lenguaje que precisemos, esta página hace la conversión por nosotros. En este ejemplo vamos a utilizar JavaScript.
fetch('http://localhost:8080/v1/chat/completions', {
method: 'POST',
headers: {
'Content-Type': 'application/json'
},
// body: '{\n"model":"ggml-gpt4all-j",\n"messages": [{"role": "user", "content": "Who is Santiago Ramón y Cajal?"}],\n"temperature": 0.9 \n}',
body: JSON.stringify({
'model': 'ggml-gpt4all-j',
'messages': [
{
'role': 'user',
'content': 'Who is Santiago Ramon y Cajal?'
}
],
'temperature': 0.9
})
});
LocalAI presenta una interfaz de conexión similar a GPT4All, pero presenta menos opciones de implementación. Aunque a diferencia de GPT4All, LocalAI usando Docker-compose, permite gestionar múltiples llamadas simultáneas. No posibilita procesarlas en paralelo, únicamente se encolan y se procesan según el orden de llegada.
Made with in Spain
© 2013 - 2026 Xoborg Technologies S.L. Todos los derechos reservados. C. Teso de San Nicolás, 17, Semisótano local 1, Salamanca 37008, Castilla y León, España.