
Este artículo forma parte de una serie de publicaciones en las que se presentan los datos destacables y conclusiones de la investigación que se ha llevado a cabo para comprobar y valorar la aplicabilidad de nuevas tecnologías, como la Inteligencia Artificial, en el ámbito médico y sanitario.
Antes de empezar, informar al lector que esta publicación presenta un carácter técnico, en el que se realizará un estudio de viabilidad económica de una posible implementación empleando estas herramientas. También, indicar que todos los valores son aproximaciones utilizando documentos inventados y que no representan elementos reales, pero que nos puede servir para saber cuál podría ser el coste real de una implementación haciendo uso de estas tecnologías.
Uno de los elementos más importantes a tener en cuenta a la hora de considerar la factibilidad del proyecto es su viabilidad económica. Dado que esta publicación es un primer acercamiento al mundo de la Inteligencia Artificial, es necesario llevar a cabo unas aproximaciones y cálculos para poder verificar si el empleo de estas tecnologías es posible en el ámbito sanitario.
Como se comentó en este artículo , los 'tokens' son la unidad individual de texto que se emplean para representar la información con el que se interacciona con un modelo de Inteligencia Artificial. De manera general, en los servicios disponibles se efectúa un cobro dependiendo del número de 'tokens' que se empleen en las conversaciones con estos modelos. Para llevar a cabo este proceso, conocido como 'tokenizar', cada modelo utiliza una forma distinta de computar y generar estos elementos. Existen diversas herramientas para simular este cálculo, entre las más populares podemos encontrar aquí de ChatGPT.
Para efectuar estos cálculos vamos a emplear la utilidad descrita con anterioridad, haciendo uso de diagnósticos de ejemplo en varios idiomas para comprobar el comportamiento de este procesador de palabras.
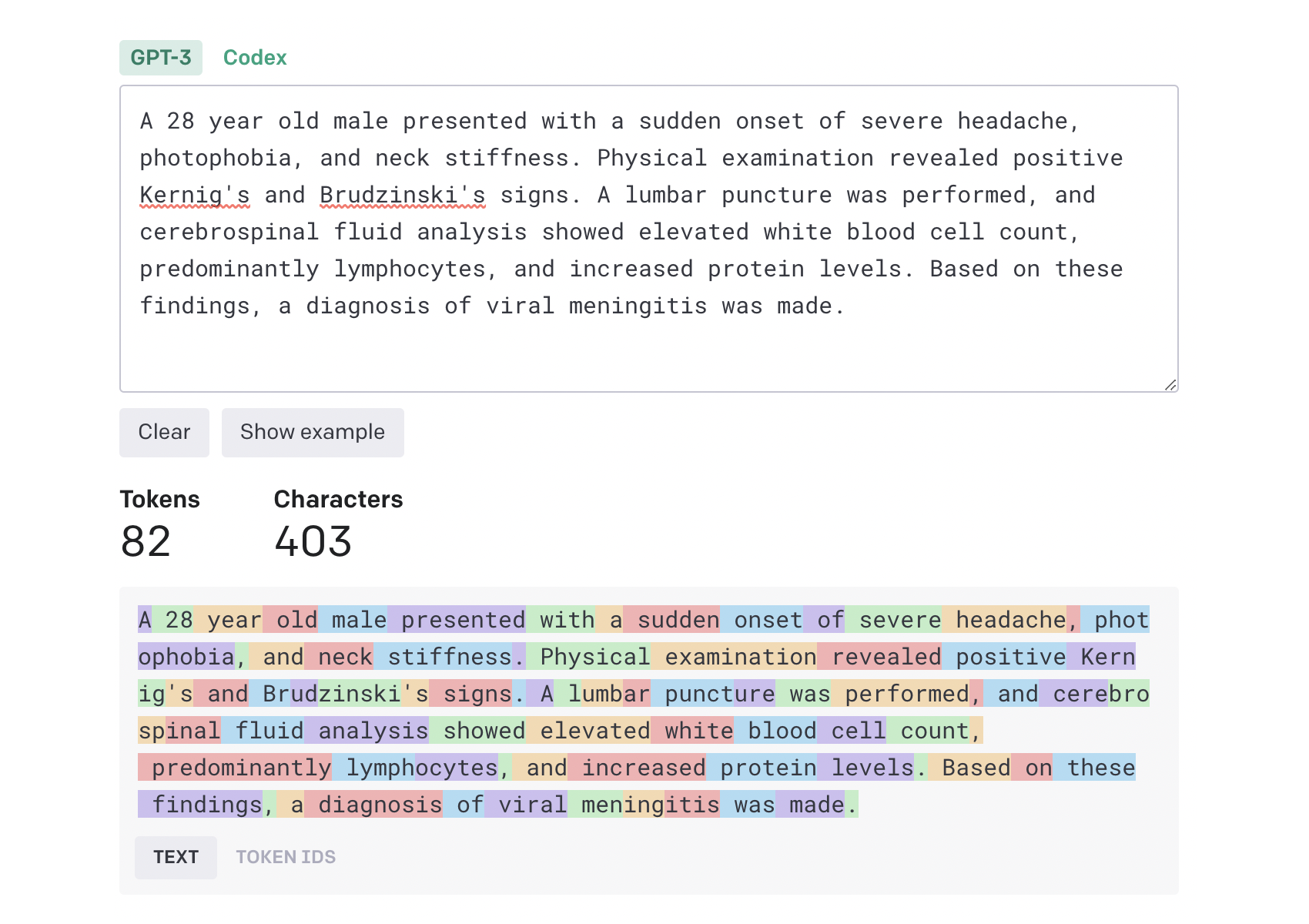
Como apreciamos en la imagen, tras introducir 403 caracteres hemos obtenido 82 tokens, fijándonos en la parte inferior de la misma captura podremos verificar la manera en la que se distribuyen los diferentes tokens. Como resultado, obtenemos que aproximadamente cada 5 caracteres en inglés representan un token.
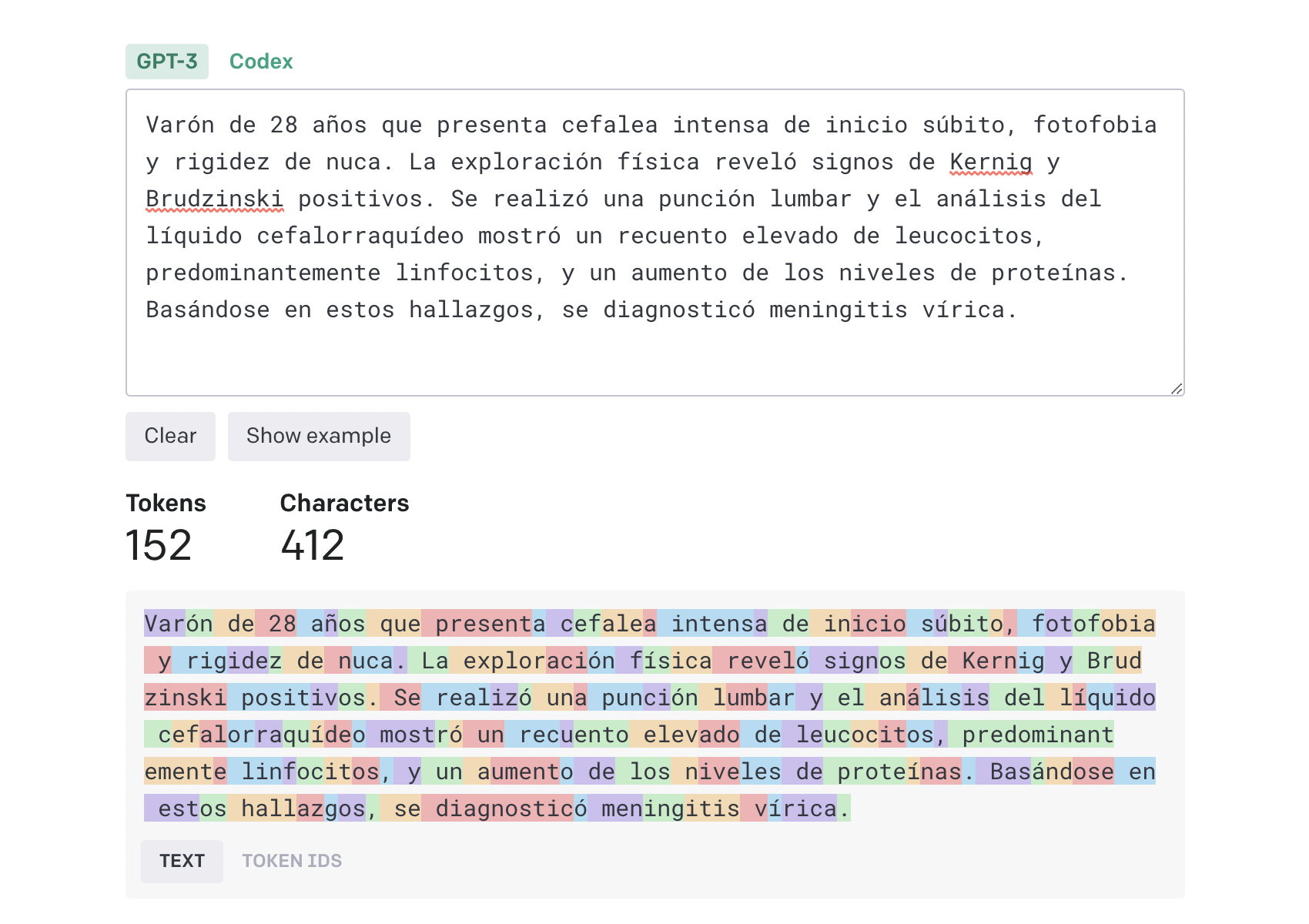
Ahora efectuaremos el mismo cálculo con el mismo texto, esta vez en castellano. En la imagen se puede ver que el número de caracteres se ha incrementado levemente hasta los 412, mientras que los tokens producidos han sufrido un fuerte cambio, elevándose hasta los 152. Estos resultados arrojan una media aproximada menor a un token cada 3 caracteres.
Como podemos ver, la diferencia es notoria, sobre todo si tenemos en cuenta la elevada cantidad de mensajes que pueden generarse en múltiples conversaciones. Se deberá comprobar la viabilidad de utilizar traducciones al inglés con el fin de generar una menor cantidad de tokens.
Esta información nos sirve para hacer una primera aproximación a los costes. Para mejorar estos cálculos y acercarnos al coste real por el uso de múltiples fragmentos de texto, se ha tomado la decisión de desarrollar un programa que procese el contenido de bloques de texto y calcule el coste aproximado por carácter y por un conjunto de oraciones.
En este proceso se ha tomado como referencia los precios del servicio Azure OpenAI.
Al analizar cien bloques de texto en castellano obtenemos los siguientes resultados.

Como se puede apreciar en la imagen, los bloques de texto están conformadas por 48.000 caracteres, siendo equivalentes a 19.544 tokens. Esto nos arroja una media de 2,45 caracteres por token, menor al cálculo realizado con anterioridad, debido seguramente a la existencia de caracteres especiales como signos de puntuación o tildes.
El procesamiento de estos bloques de información conllevaría un coste aproximado de 0,04 $ haciendo uso de GPT-3.5-turbo. Es importante recordar que estos datos son aproximaciones, ya que no se tienen en cuenta los tokens necesarios para las respuestas ni las ejecuciones parciales y repetitivas.
Ahora llevaremos a cabo una extrapolación a un número mucho mayor, para reflejar una mayor introducción de caracteres, en este caso 50.000 bloques. Utilizando como referencia los bloques anteriores, podemos aproximar que cada uno de ellos está formado por unos 480 caracteres (77 palabras) o 195 tokens. Partiendo entonces de estos datos, obtenemos los siguientes resultados.
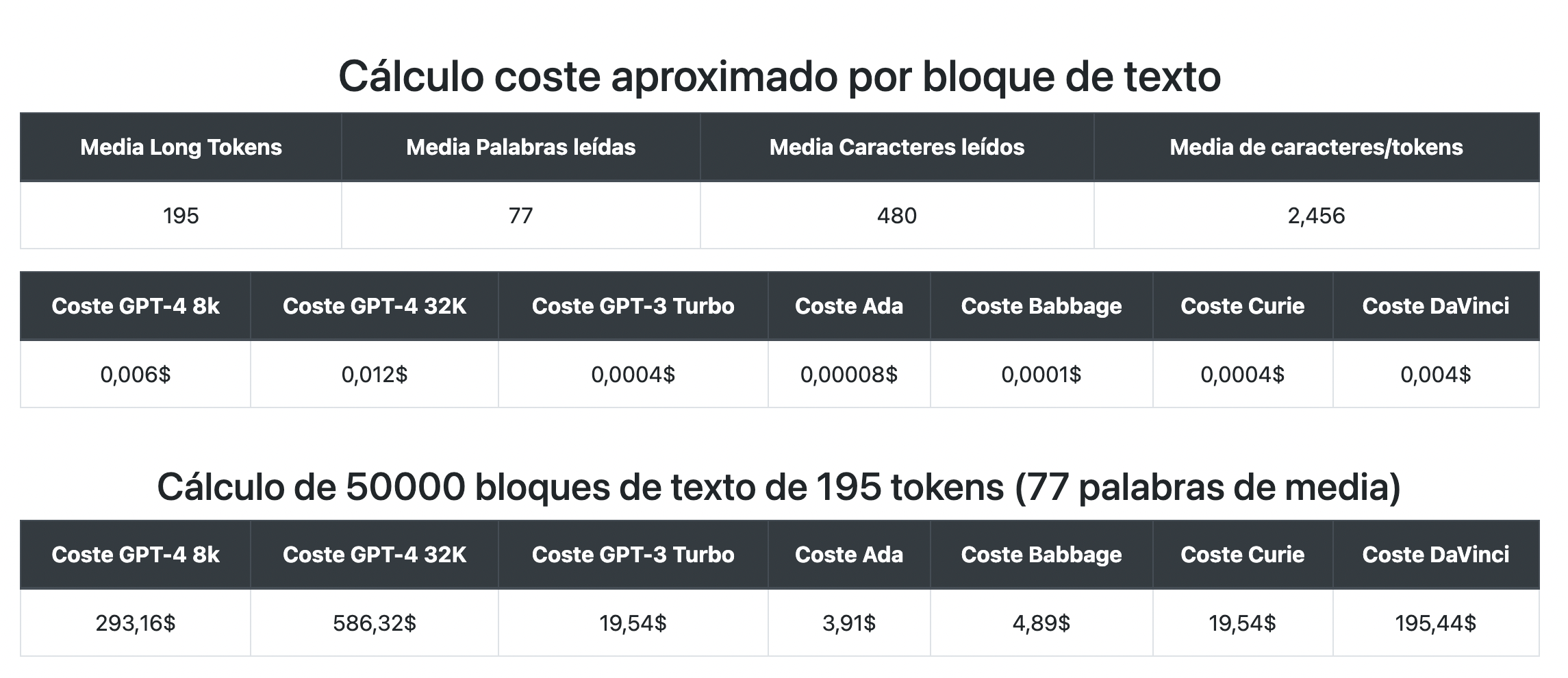
Como se aprecia en la imagen, el procesamiento de estas historias presenta una gran variedad de costes dependiendo del modelo que empleemos. El más recomendado para esta solución, tanto a nivel técnico como a nivel económico, es hacer uso de GPT-3.5-Turbo, uno de los modelos más populares de OpenAI. Ahora, para comprobar la hipótesis mencionada con anterioridad, efectuamos otra aproximación con varios bloques de texto, esta vez en inglés.
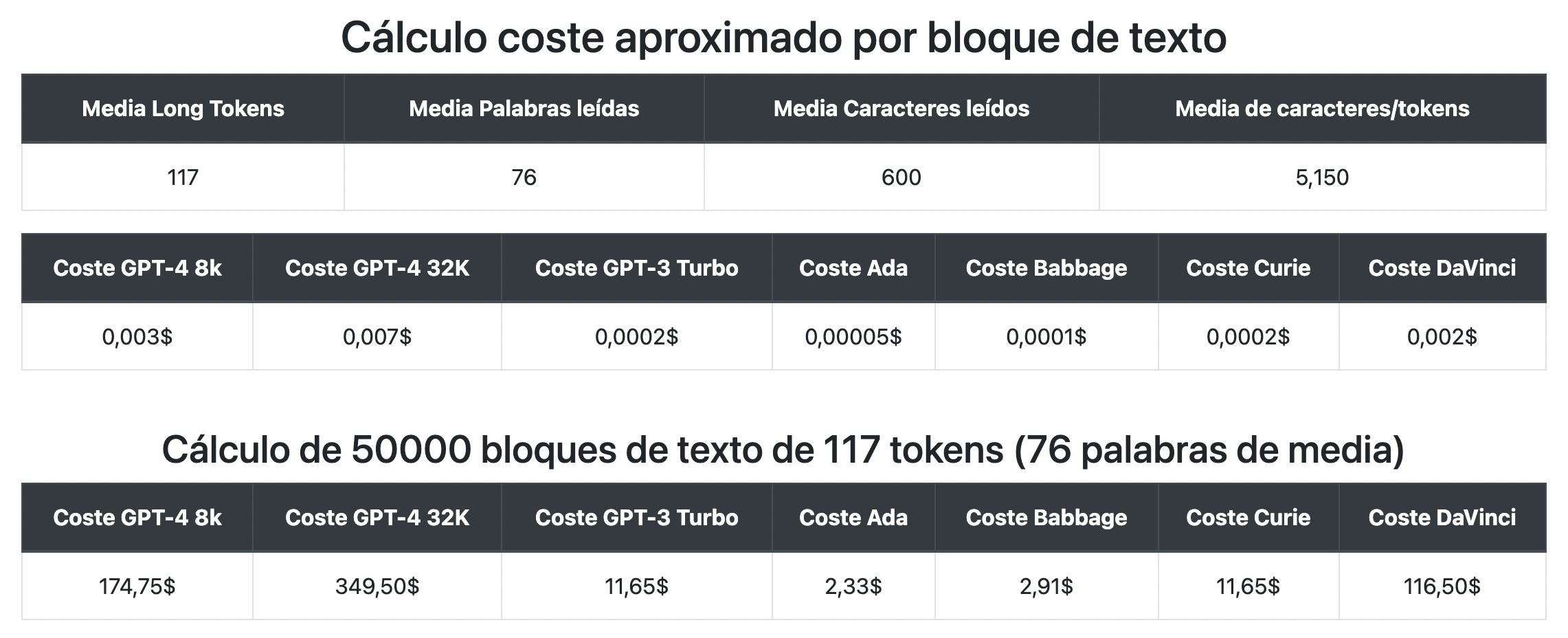
En la imagen podemos ver que, en efecto, existe una gran diferencia entre los dos idiomas. En este caso se han procesado por bloque de texto unos 600 caracteres obteniendo 117 tokens, es decir, cada token es representado por más de 5 caracteres. Por tanto, se han escrito un 25% más de caracteres en inglés, pero se han obtenido un 67% menos de tokens. Es decir, en promedio, en castellano se genera el doble de tokens por carácter que en inglés.
Estos hallazgos nos llevan a la conclusión de que es posible emplear un sistema que traduzca el contenido al inglés antes de ser enviado como enunciado, y que la Inteligencia Artificial responda en el idioma deseado, en teoría, reduciendo los costes computacionales. En este estudio se han tenido en cuenta las soluciones más populares de traducción como DeepL, Google Translator y Azure Translator.
Si ahora realizamos un cálculo con los valores anteriores, que superan los 24 millones de caracteres, obtenemos que utilizar estas herramientas puede acarrear un coste mucho más elevado, superando los 200€, que el de emplear el texto en el idioma original.
Debido a este descubrimiento, es recomendable el uso de la información en castellano, o el idioma nativo del sistema, y no realizar traducciones al inglés, si no es estrictamente necesario, si trabajamos con una amplia cantidad de información. En las pruebas efectuadas se ha llegado a la conclusión de que es posible hacer uso del inglés en algunos prompts, como puede ser el de configuración del sistema o los de ejemplo de conversaciones, ya que se trata de información que siempre se envía una única vez por conversación y puede presentar un pequeño ahorro.
Como hemos podido comprobar, es posible emplear la Inteligencia Artificial en proyectos con grandes cantidades de información. Debemos saber elegir el modelo que mejor se adecue a nuestros requerimientos técnicos y económicos. Siendo los modelos que presentan un mayor importe, generalmente, más completos.
También recalcar que si trabajamos con un amplio volumen de datos no es recomendable el empleo de traducciones en todo el texto, ya que conlleva un coste mayor y no existe un cambio sustancial en el comportamiento de estos sistemas porque la mayoría han sido entrenados en diversos idiomas. Para finalizar, simplemente volver a indicar que para la obtención de los valores de este artículo no se ha utilizado documentos o valores reales, se ha hecho uso de elementos de prueba diseñados para esta tarea.
Made with in Spain
© 2013 - 2026 Xoborg Technologies S.L. Todos los derechos reservados. C. Teso de San Nicolás, 17, Semisótano local 1, Salamanca 37008, Castilla y León, España.